
Snowflake
Snowflake to hurtownia danych (snowflake data warehouse) wybierana przez organizacje, które chcą zmaksymalizować swoje możliwości analityczne.
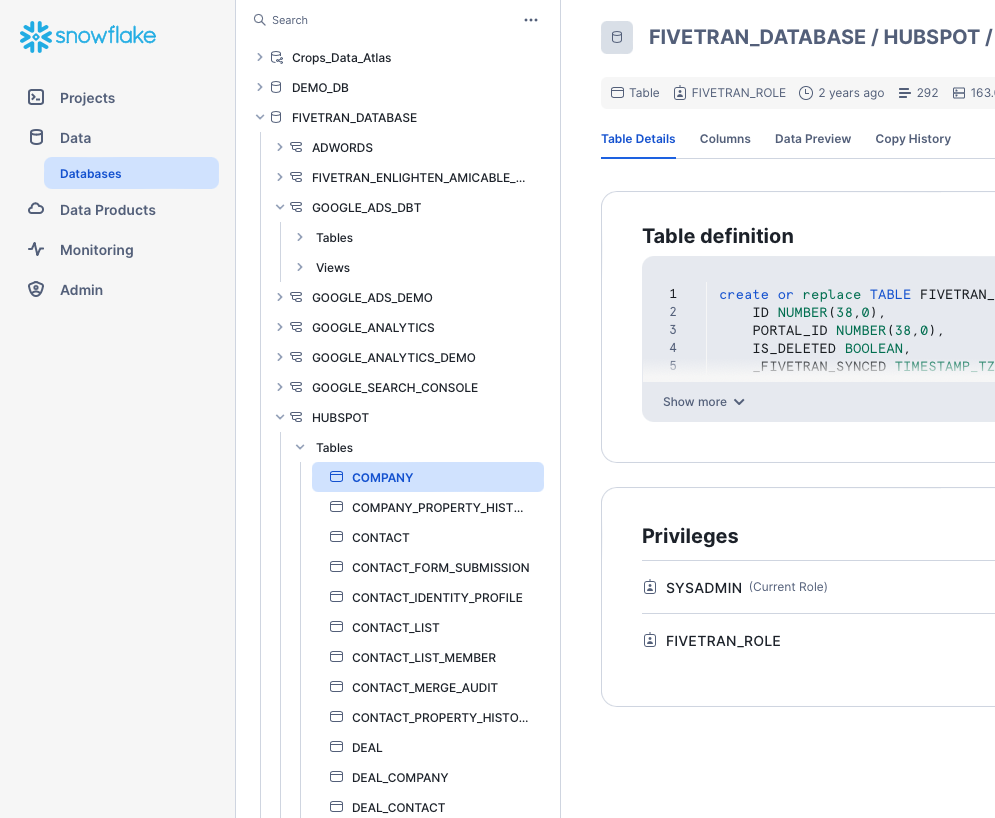
Big data w chmurze - prosty dostęp do danych dla wszystkich użytkowników.
Dzięki Snowflake firmy uzyskują dostęp do szerokiej gamy funkcji analitycznych, które są scentralizowane, bezpieczne i dostępne z dowolnego miejsca na świecie.
Hurtownia danych, jakiej potrzebujesz.
Zarządzanie bazą danych
Środowisko chmurowe działa u wybranego dostawcy (Microsoft, AWS, Google), co oznacza eliminację obciążenia związanego z zarządzaniem infrastrukturą.
Wysoka wydajność
Niezależnie od tego, ile danych przetwarzasz, możesz robić to o wiele sprawniej niż dotychczas. Dzięki wbudowanej optymalizacji wydajności podejmujesz lepsze i szybsze decyzje biznesowe.
Nieograniczone zapytania
Dostęp dla wszystkich! Snowflake idealnie sprawdzi się w pracy data scientistów, analityków czy kierowników projektów, oferując jedną platformę i jedno źródło prawdy.
Powiązane narzędzia
Łatwość obsługi
Snowflake zapewnia prostotę w konfiguracji, zarządzaniu i korzystaniu z danych. Dzięki temu nawet użytkownicy bez zaawansowanej wiedzy technicznej mogą skorzystać z zaawansowanych funkcji analizy danych.
Separacja mocy obliczeniowej od pamięci masowej
Snowflake oddziela moc obliczeniową od pamięci masowej, co umożliwia lepszą skalowalność i efektywne wykorzystanie zasobów. Odpowiedni dobór parametrów może obniżyć koszty narzędzia.
Zaawansowana architektura
Snowflake umożliwia korzystanie z architektury, która pozwala użytkownikom przechowywać dane w różnych chmurach publicznych (np. AWS, Azure, Google Cloud) jednocześnie. To elastyczne podejście daje większą swobodę w wyborze dostawcy chmury.
DlaczegoSnowflake?
Elastyczność skalowania
Snowflake umożliwia elastyczne skalowanie zasobów, co pozwala dostosować wydajność magazynu danych do bieżących potrzeb. Użytkownicy płacą tylko za rzeczywiste zużycie zasobów, co może przyczynić się do optymalizacji kosztów.
Architektura wielopoziomowa
Platforma Snowflake wykorzystuje innowacyjną architekturę wielopoziomową, co przekłada się na wysoką wydajność zapytań i przetwarzanie równoległe. To umożliwia szybki dostęp do danych nawet przy dużej ilości jednoczesnych użytkowników.
Bezpieczeństwo danych
Snowflake dba o bezpieczeństwo danych na wielu poziomach, obejmując dostęp do danych, szyfrowanie oraz zarządzanie kluczami. Platforma spełnia różne standardy bezpieczeństwa, co jest istotne zwłaszcza dla przedsiębiorstw obsługujących poufne informacje.
Sprawdź gotowe rozwiązania dla Twojej branży — dashboardy live.
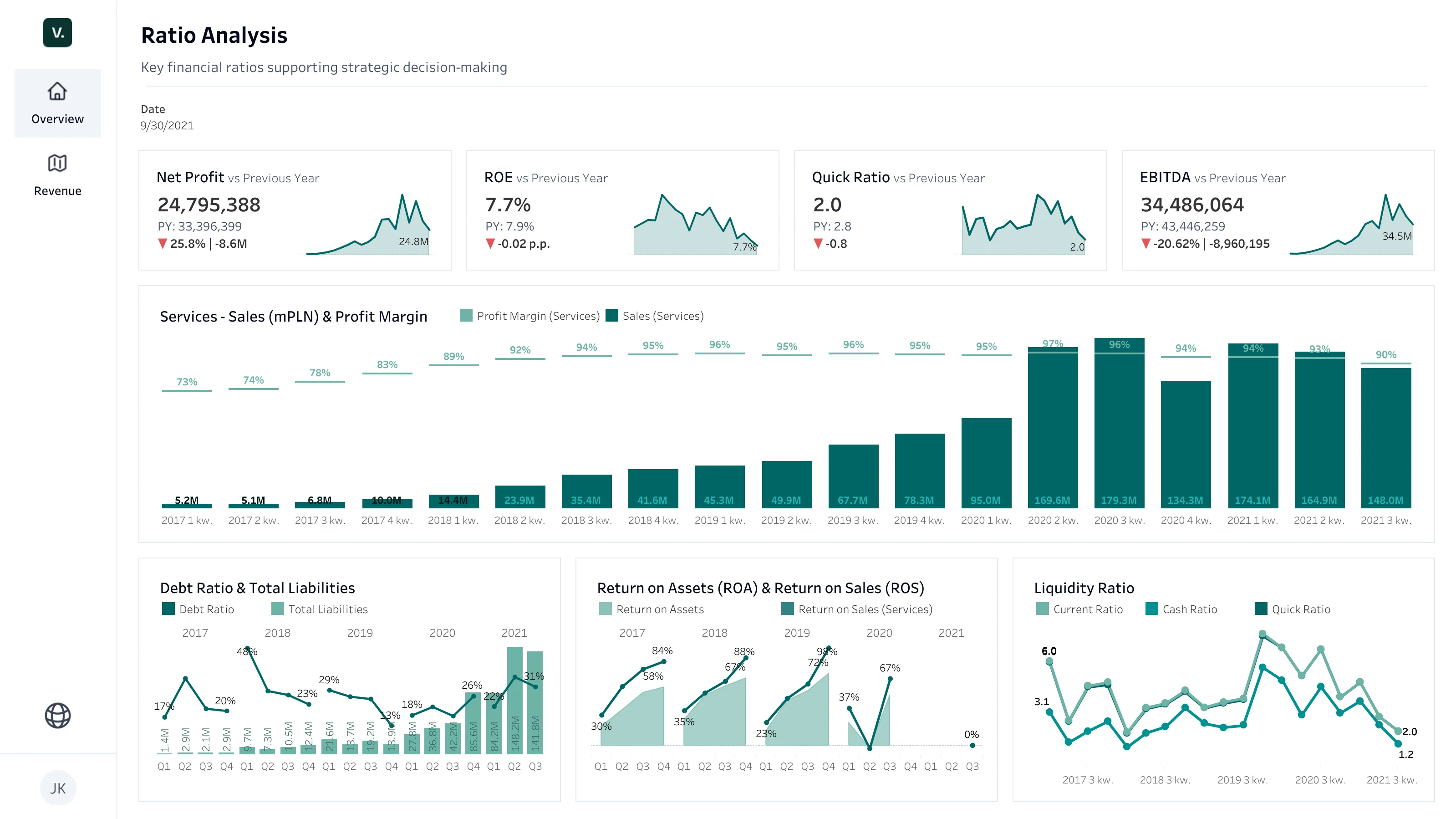
Dashboard finansowy
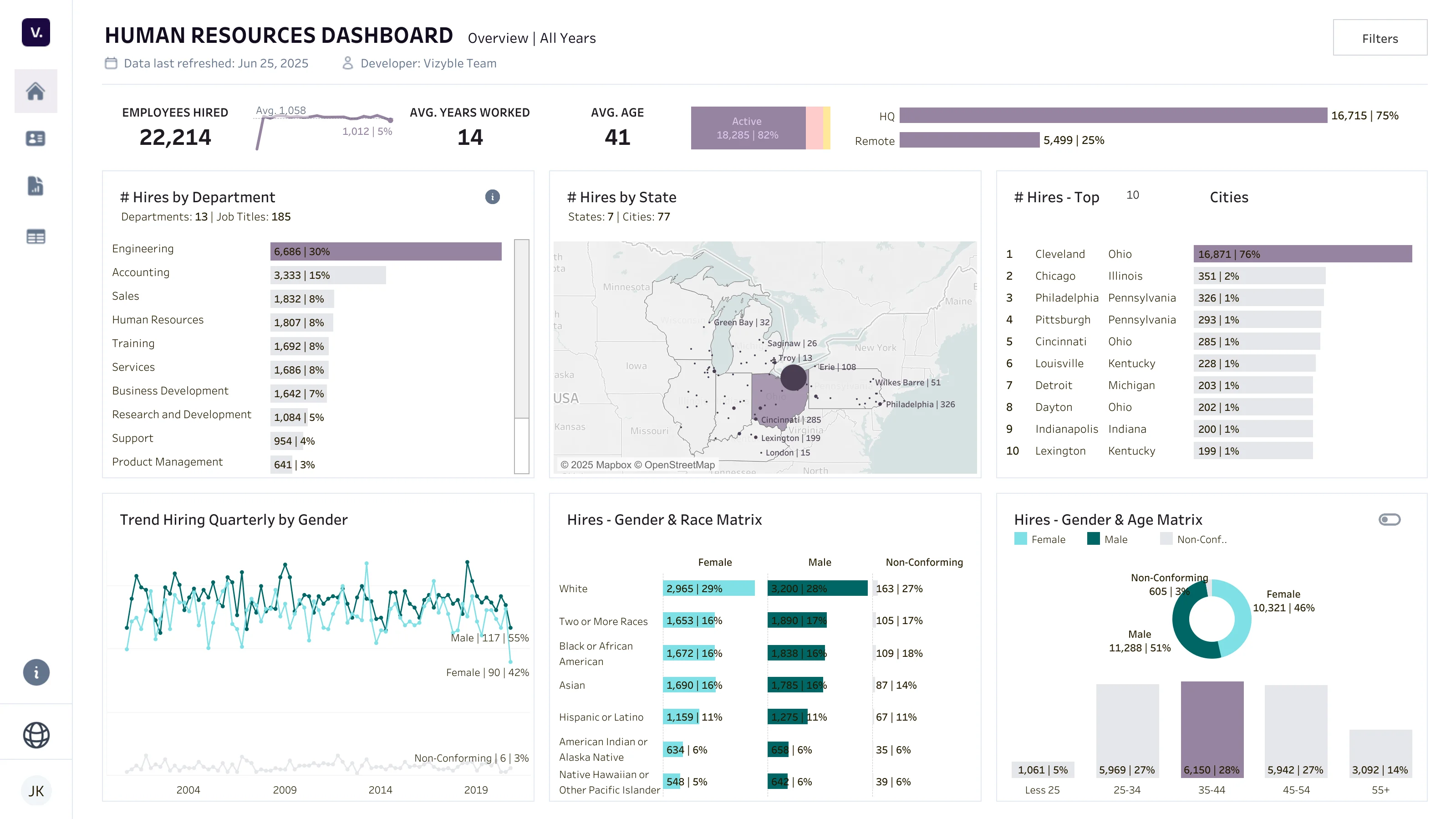
Dashboard dla HR
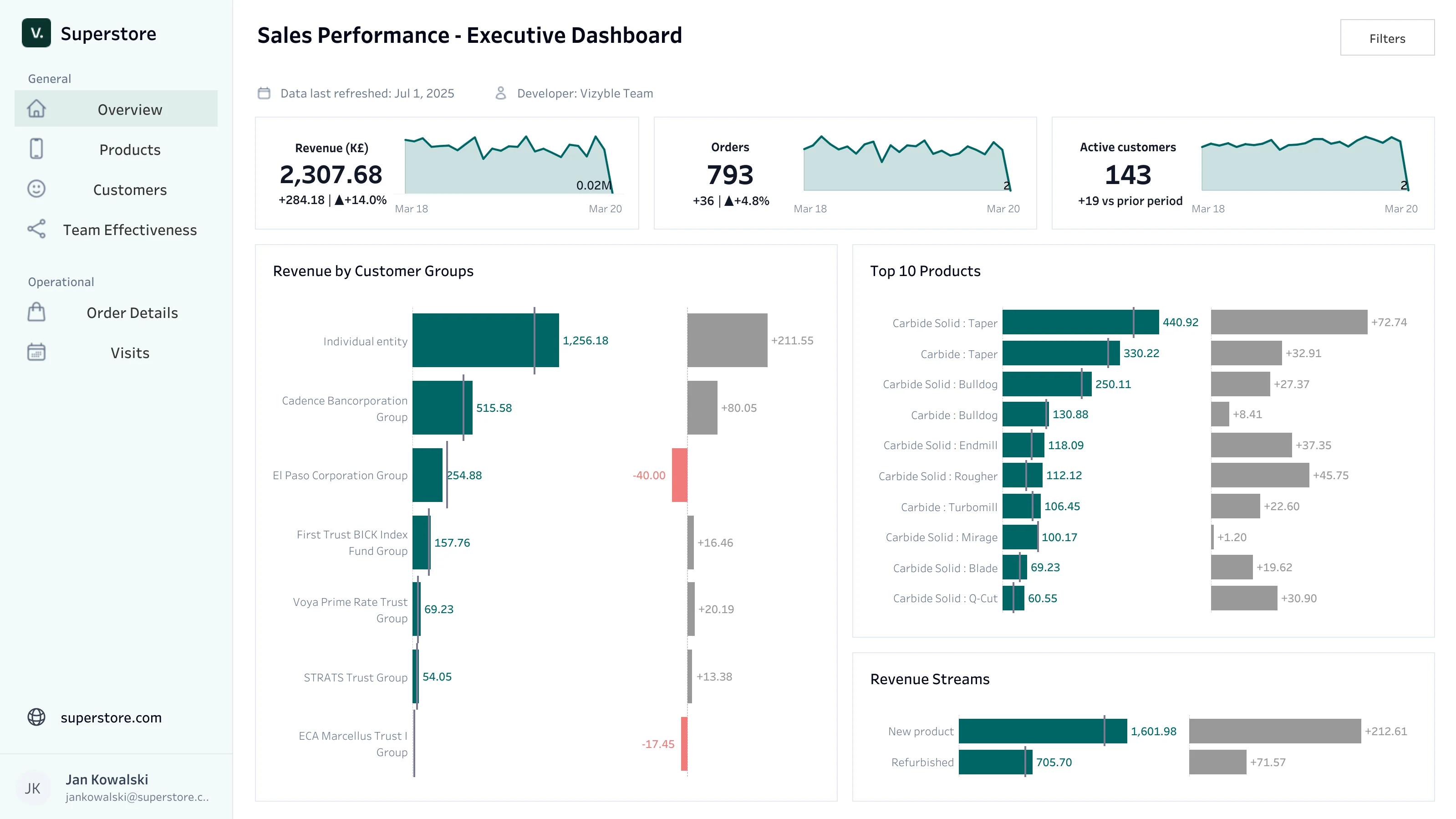
Dashboard sprzedażowy
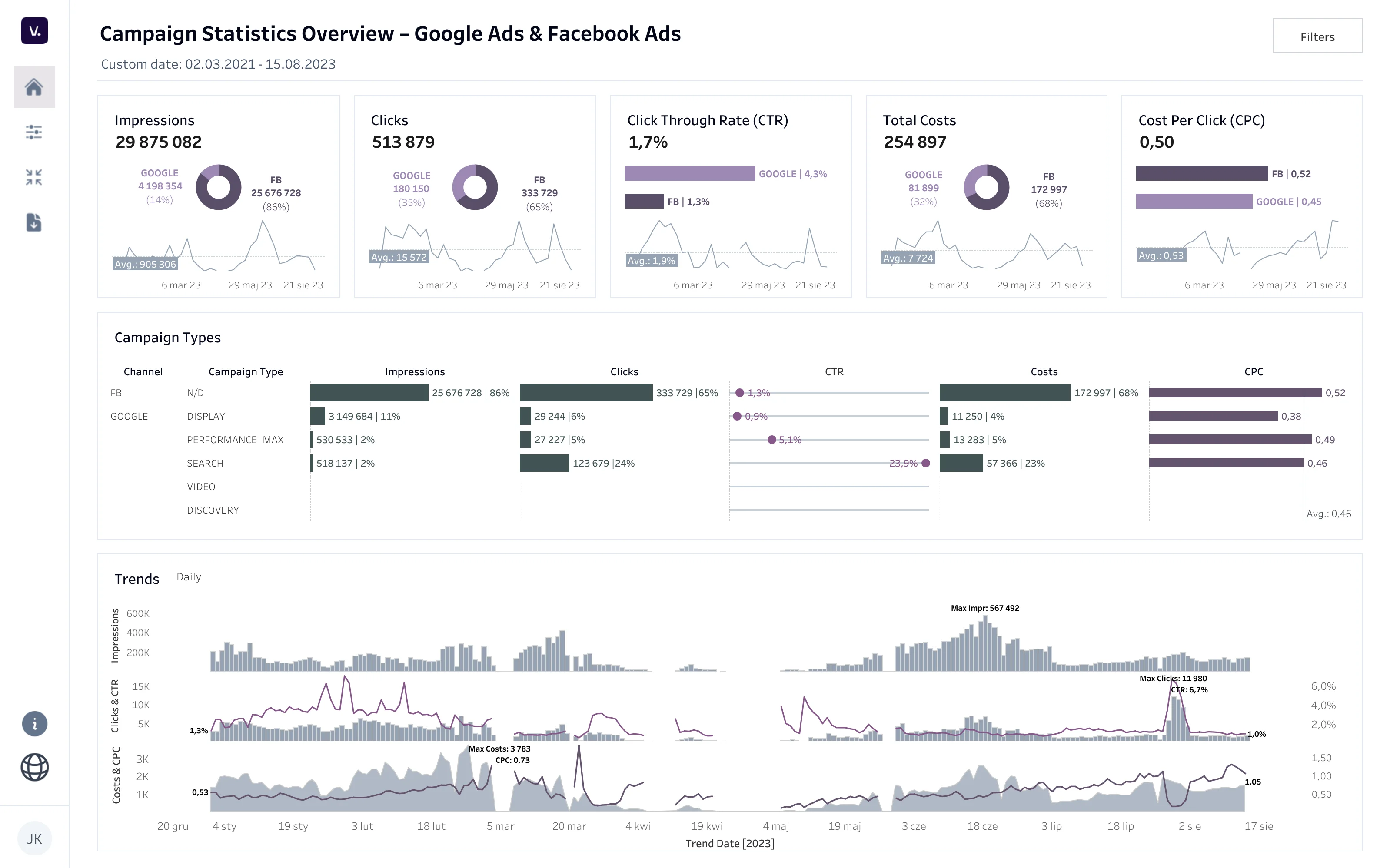
Dashboard marketingowy
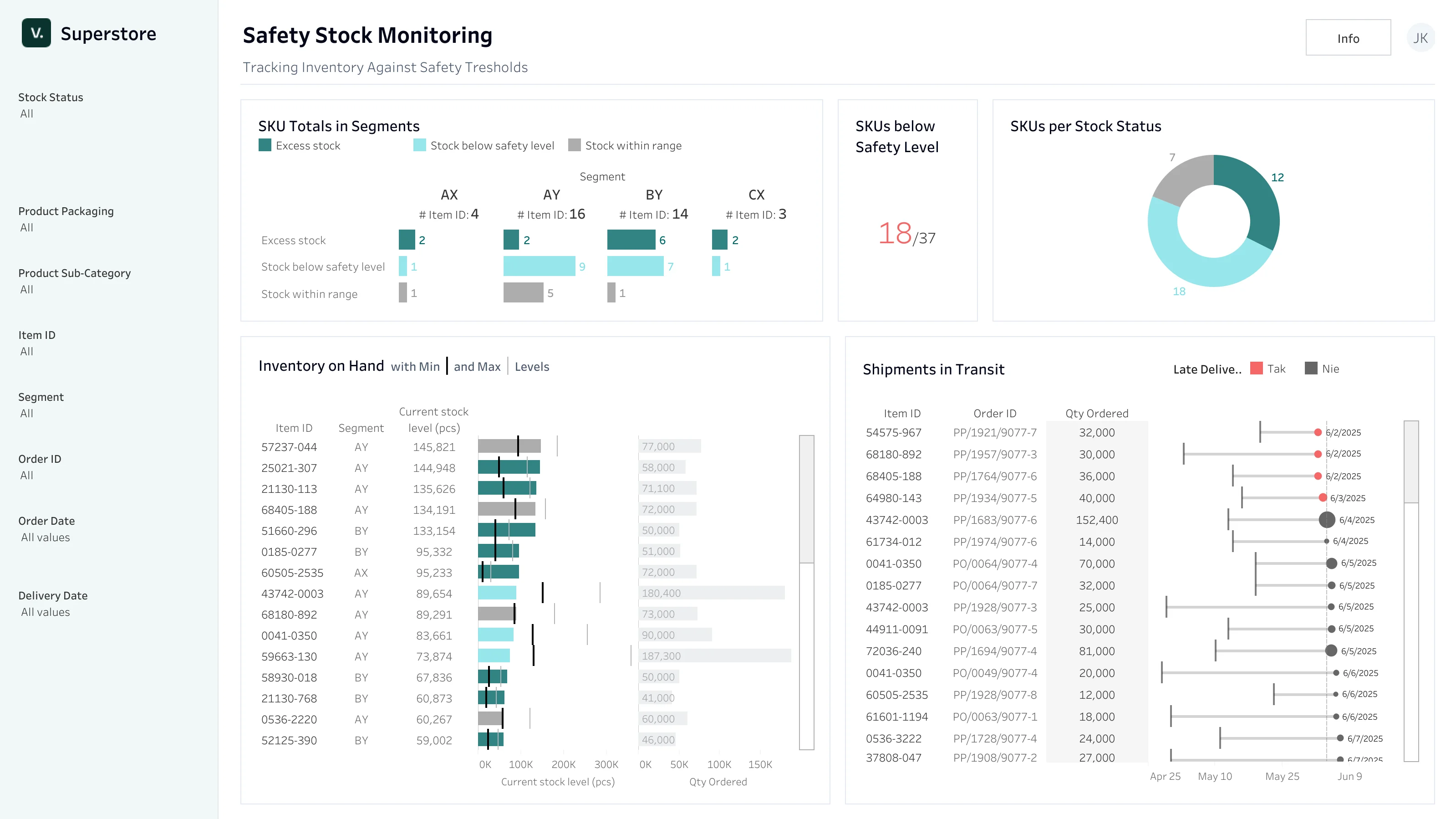
Dashboard dla logistyki
Dashboard dla produkcji

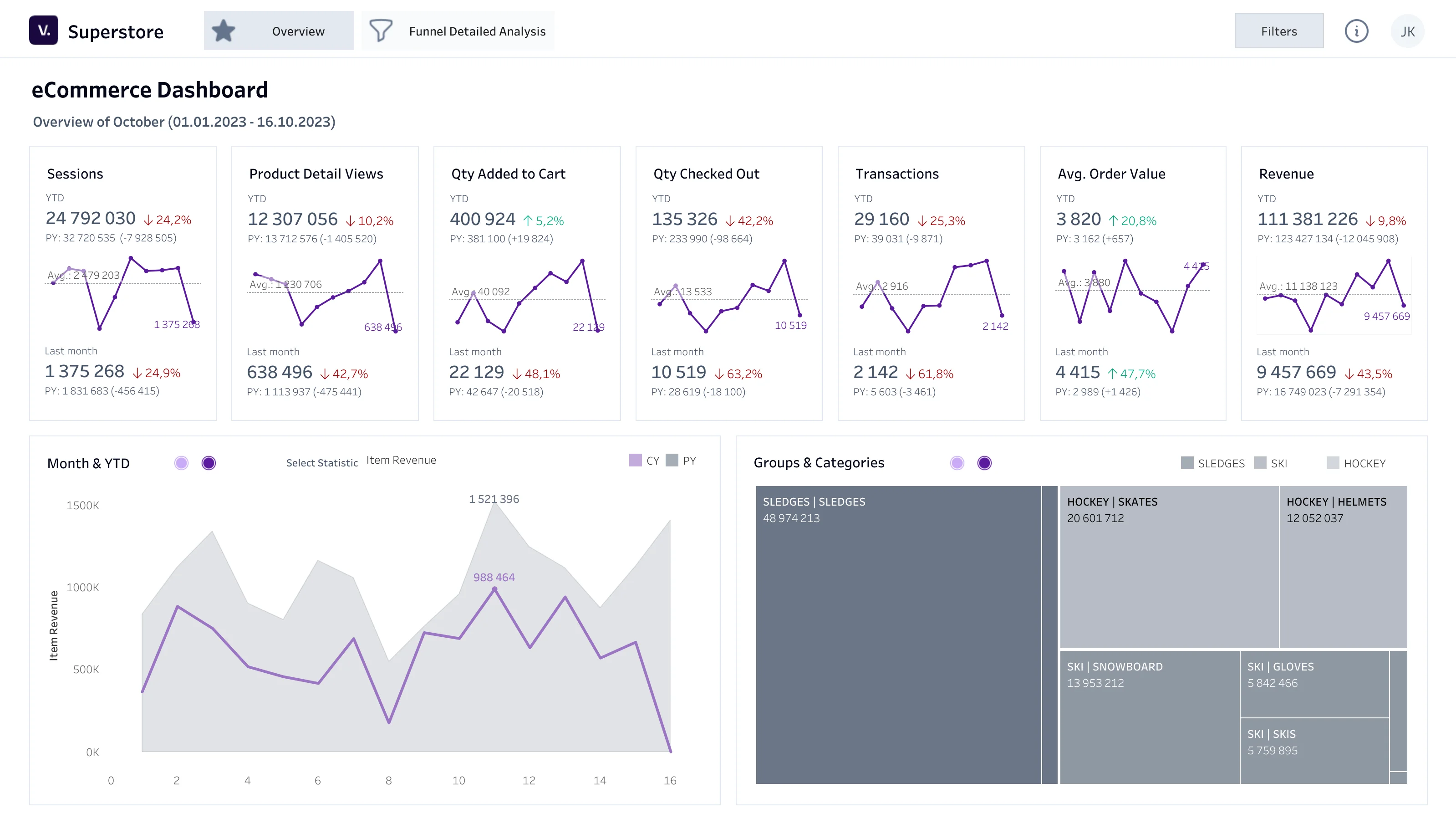
Dashboard dla e-commerce




FAQ.
Znajdź odpowiedź na swoje pytanie.
Snowflake to oparta na chmurze platforma hurtowni danych, która umożliwia użytkownikom przechowywanie, zarządzanie i analizowanie dużych ilości danych z zachowaniem skalowalności, wydajności i współbieżności.
Architektura Snowflake oddziela pamięć masową i obliczenia, umożliwiając użytkownikom niezależne skalowanie zasobów, co przekłada się na lepszą wydajność, opłacalność i elastyczność.
Snowflake jest dostępny na popularnych platformach chmurowych, takich jak Amazon Web Services (AWS), Microsoft Azure i Google Cloud Platform, oferując użytkownikom wybór i elastyczność.
Snowflake obsługuje różne formaty danych, w tym JSON, Avro, Parquet, CSV i inne, ułatwiając płynne ładowanie i pozyskiwanie danych z różnych źródeł.
Chociaż Snowflake doskonale radzi sobie z obciążeniami związanymi z analizą danych na dużą skalę, może nie być zoptymalizowany pod kątem analizy w czasie rzeczywistym ze względu na swój charakter przetwarzania wsadowego.
Snowflake nadaje priorytet bezpieczeństwu danych dzięki funkcjom takim jak szyfrowanie w spoczynku i podczas przesyłania, kontrola dostępu oparta na rolach i certyfikaty zgodności w celu ochrony poufnych informacji.
Wieloklastrowa, współdzielona architektura danych Snowflake umożliwia użytkownikom jednoczesne uruchamianie różnych obciążeń z wysokimi poziomami współbieżności bez pogorszenia wydajności.
Tak, Snowflake automatyzuje skalowanie zasobów w oparciu o wymagania obciążenia, zapewniając optymalną wydajność i opłacalność bez ręcznej interwencji użytkowników.
Snowflake zapewnia kompleksowe wsparcie poprzez dokumentację, zasoby szkoleniowe, bazę wiedzy, fora społeczności i dedykowany zespół obsługi klienta.
Aby rozpocząć korzystanie ze Snowflake, zarejestruj konto na preferowanej platformie w chmurze, załaduj dane do tabel Snowflake i napisz zapytania SQL w celu analizy danych.